How to discover RNA-targeted drugs with AI
This is the brief explainer post. Details in the paper. Back to directory.
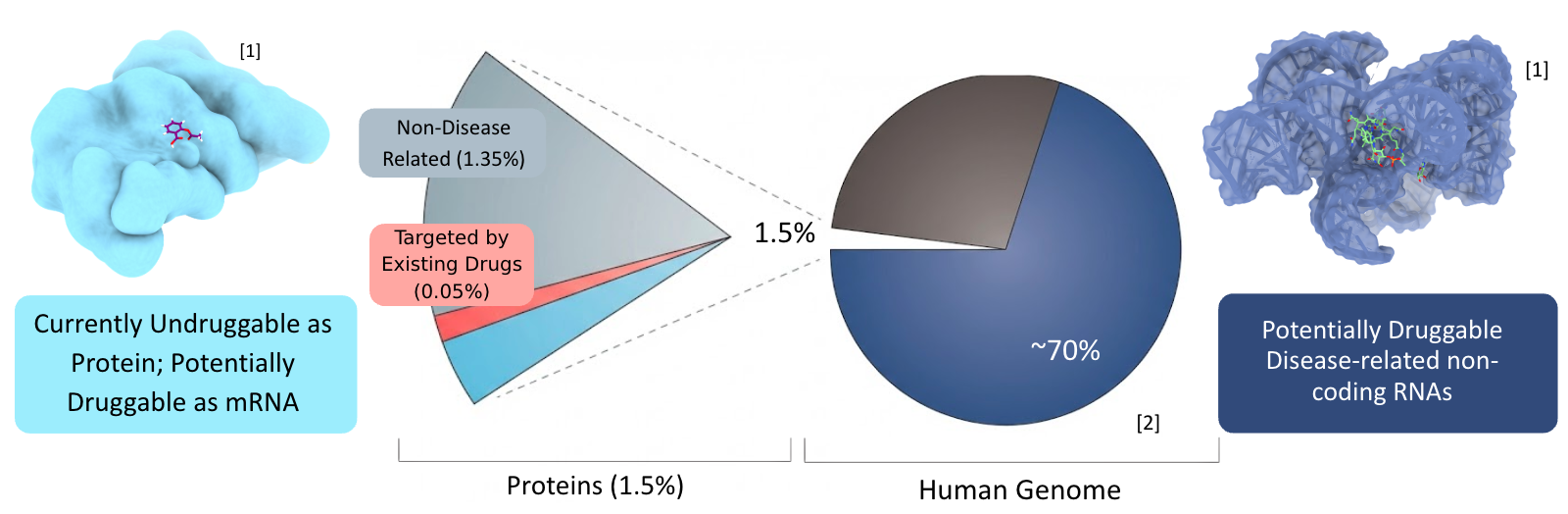
We’ve made tremendous progress conquering disease, with all the types of drugs we have today — penicillin, aspirin, metformin — but what if we could target 1400x more?
Right now, almost every drug works by binding small molecules to pockets in disease-causing proteins. Proteins, since they’re simpler and better understood.
- Emphasize the strong potential of this project
- Encourage funding at least 20,000, not just for computational resources but experimental validation. But many proteins in critical diseases don’t have pockets to bind to, like c-MYC in cancers, RNA-driven Huntington’s, or Ehlers-Danlos (mine). The only druggable sites are in the RNAs.
So we need to find drugs that bind to a specific RNA. The problem is, testing physically with bulky machines costs millions and takes months, so the research has directed towards deep learning to predict binding affinity to help us screen candidates much faster.
Unfortunately, RNA behaves more complexly than proteins and has far less experimental data, making it much harder for AI to model. Current attempts are interesting but not reliable enough to use.
As such, RNA has become a neglected area, with most ML researchers focusing on protein problems instead, waiting for lab data to catch up.
What I realized is that although knowing where drugs bind to RNAs would be ideal (that’d help us ultimately design drugs computationally), we only really need to know how strongly drugs bind (binding affinity) to narrow down molecule candidates and speed up the discovery process at this stage. And testing for binding affinity doesn’t inherently require 3D structures. So testing out different architectures, I’ve found that by just adapting recent insights in ML to the RNA problem, we can make meaningful progress even at the current state of limited data!
Which insights?
- Evolutionary history is critical for AlphaFold when predicting protein structure. We can use evolutionary history and other rich alternative encodings (e.g. language model embeddings) to proxy 3D RNA structure implicitly.
- To effectively fuse signals, we can use a gated co-attention (adapted from Flamingo vision-language model) to let the model learn which signals matter most in a way that parallels how molecules actually bind to RNAs.
- If we can provide not just binding affinity but also a confidence score, that lets researchers avoid false positives (saving time/money). Then using this confidence score, we can let the model safely teach itself on new high-quality examples.

This new approach (which I call “RiboLead” for generating leads for ribo-drugs) reaches 96% accuracy! Its performance on standard RSIM benchmarks like 5-fold cross validation far surpass DeepRSMA (SoTA, released a year ago), in addition to tests on unseen RNAs and diseases.
Finally, I wanted to validate if it could work irl, so I tested it on infectious intestinal bacteria Clostridium, and it actually (confidently) identified valid a valid binder!
Next step: experimental data curation